Llama 2와 Llama 2-Chat
Llama 2는 공개형 사전학습 언어모델 계열이다. Llama 2-Chat은 여기에 대화형 정렬을 더한 모델이다. 초점은 성능 수치보다 학습 절차에 있다. 공개형 모델이 대화형 제품에 가까워지기까지 어떤 단계가 필요한지 한 흐름으로 정리한다.
모델 규모와 사전학습
모델은 7B, 13B, 34B, 70B 네 크기로 학습됐다. 사전학습 토큰은 2조 개다. 문맥 길이는 4k로 늘었고, 34B와 70B에는 GQA가 들어간다. 데이터는 공개 온라인 소스에서 수집했다. Meta 제품 데이터는 넣지 않았다. 사실성 높은 소스를 더 많이 섞어 환각을 줄이려는 방향도 같이 잡았다.

표에는 모델 크기와 사전학습 토큰 수, 문맥 길이, GQA 적용 여부가 함께 정리돼 있다.
대화형 정렬 과정
대화형 모델은 세 단계를 거쳐 만들어진다. 고품질 SFT 데이터 27,540개로 기본 응답 형식과 말투를 맞춘다. 사람 선호 비교 데이터를 모아 도움성 보상모델과 안전성 보상모델을 따로 학습한다. 그다음 rejection sampling과 PPO를 반복해 정책을 다듬는다. 정책이 바뀔 때마다 선호 데이터도 다시 모은다. 최신 응답 분포에 맞는 보상모델을 유지하려는 목적이다.
다중 턴 대화에서는 Ghost Attention이 쓰였다. 처음 넣은 시스템 지시가 뒤쪽 턴에서도 남도록 대화 데이터를 다시 짜는 방식이다. 짧게 답하라는 지시나 특정 역할을 유지하라는 지시가 길게 이어지게 만든다.
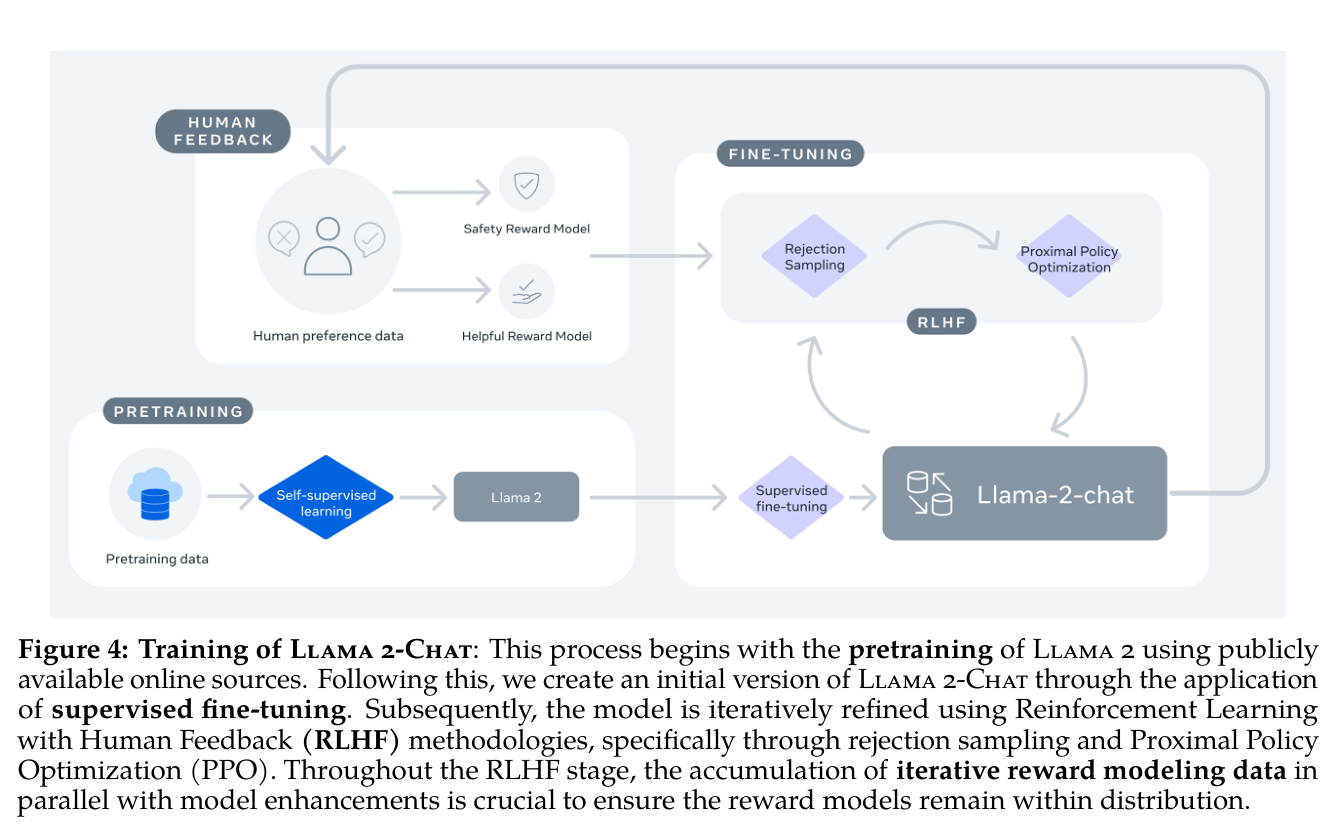
사전학습 뒤에 SFT, 보상모델 학습, RLHF가 어떤 순서로 이어지는지 묶은 그림이다.
성능 평가
사전학습 모델은 공개형 foundation model 가운데 상위권 성능을 냈다. 70B는 Llama 1 65B보다 MMLU와 BBH에서 눈에 띄게 오른다. 대화형 모델은 사람 평가에서 공개형 대화 모델보다 높은 선호를 얻었다. 7B는 MPT-7B-Chat보다 앞섰고, 34B는 Vicuna-33B와 Falcon-40B보다 높은 승률을 기록했다. 70B는 ChatGPT와 비교해도 동률 비중이 적지 않았다.
평가 범위에는 한계가 있다. 실제 서비스 전체를 대표하지 않는다. 코딩과 수학 같은 영역도 충분히 포함되지 않았다. 결과는 상대적 위치를 읽는 기준으로 남는다.

사람 평가 결과를 묶은 그림이다. 공개형 대화 모델과의 격차가 어느 정도 줄었는지 수치로 정리돼 있다.
안전성 조정과 남은 한계
안전성은 사전학습과 미세조정 두 단계에서 함께 다뤄진다. 사전학습 데이터는 영어 비중이 높고 편향과 독성도 남아 있다. 이를 뒤 단계에서 제어하는 방식이 선택됐다. 미세조정 단계에서는 안전 응답 SFT, safety RLHF, context distillation, red teaming이 함께 들어간다. 레드팀에는 350명 넘게 참여했다. 범죄, 무기, 사이버 악용, 허위정보, 비영어 프롬프트까지 폭넓게 점검했다.
적대적 프롬프트 약 2,000개로 진행한 안전성 평가에서는 경쟁 모델보다 낮거나 비슷한 수준의 위반 비율이 나왔다. 멀티턴 대화에서도 비교적 안정적이었다. 자격 없는 조언 범주에서는 위반이 더 자주 나왔다. 영어 중심 데이터와 평가라는 한계도 남아 있다. 실제 배포 환경에서는 별도 테스트와 추가 조정이 필요하다.
[이미지 삽입: safety_eval_results.png]
적대적 프롬프트를 넣었을 때 안전 기준을 얼마나 자주 어기는지 정리한 그림이다. 위반 비율과 평균 평점을 함께 놓아, 짧게 거절하는 쪽과 안전성을 지키면서 답변 품질도 유지한 쪽을 구분해 읽을 수 있다.
'AI논문' 카테고리의 다른 글
| Hybrid Flow (0) | 2026.04.14 |
|---|---|
| nemotron cascade 2 (0) | 2026.04.14 |
| RLVR (0) | 2026.04.14 |
| Attention is all you need (1) | 2026.04.14 |
| AI 논문을 읽을 때 많이 나오는 용어 정리 (1) | 2026.04.05 |